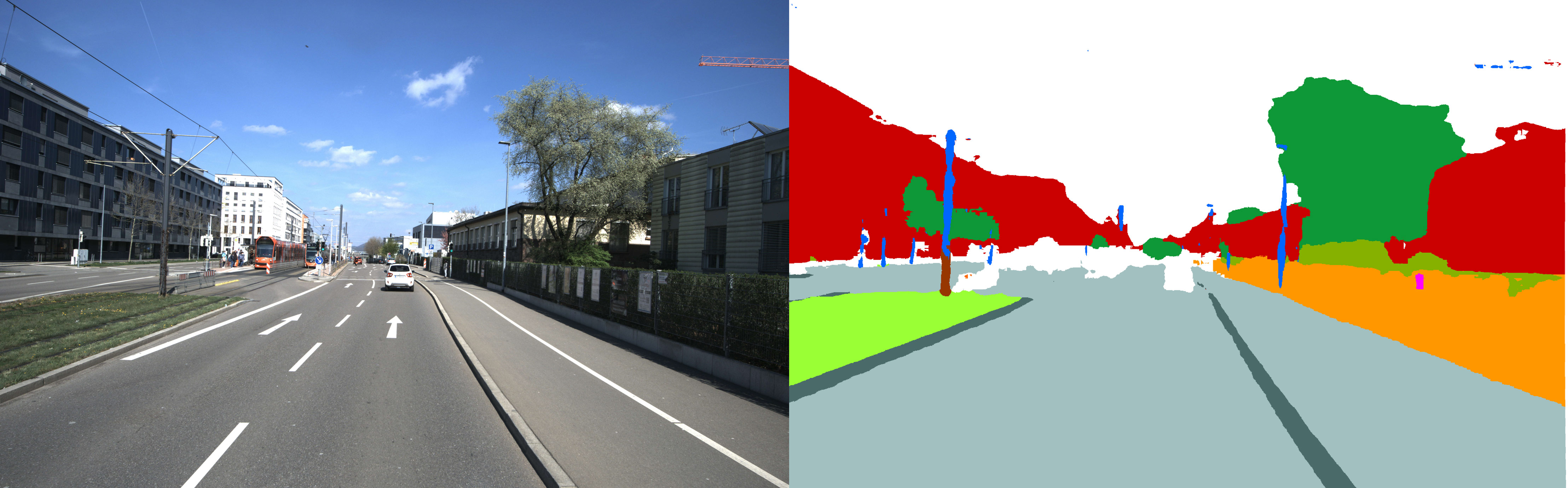


Deep Learning für die automatisierte Auswertung von Kamerabildern und Punktwolken
Bei der Zustandserfassung von Großstrukturen wie Verkehrswegen, Bauwerken oder landwirtschaftlich genutzten Flächen fallen enorme Mengen Bild- und 3D-Daten an, die heute in der Regel manuell ausgewertet werden. Das ist zeitaufwändig und teuer. Deshalb setzt Fraunhofer IPM auf eine automatisierte Auswertung mit Ansätzen des »Deep Learning«. Ergebnis ist eine semantische Segmentierung von Bildern oder Punktwolken, bei der jedes Pixel bzw. jeder 3D-Punkt einer bestimmten Objektklasse zugeordnet wird.
»Deep Learning« ist als Methode des »Machine Learning« ein Teilbereich der künstlichen Intelligenz, bei der mit lernenden Algorithmen gearbeitet wird. Das Identifizieren und Klassifizieren von Objekten, wie beispielsweise die Erkennung eines vordefinierten Objekts (z. B. ein Verkehrsschild) in einem Bild, erfolgt anhand von Trainingsdatensätzen. Der Ansatz basiert auf künstlichen neuronalen Netzen (KNN) und ist klassischen Methoden der Objekterkennung überlegen.
Mithilfe annotierter Trainingsdaten werden für bestimmte Eingangsmuster zugehörige Ausgabemuster erlernt. Auf Basis dieser »Erfahrungswerte« können neuartige Eingangsdaten dann in Echtzeit analysiert werden. Dabei erweisen sich KNN als sehr robust gegenüber Variationen charakteristischer Farben, Kanten oder Formen.
Datenbasis für die automatisierte Objekterkennung können sowohl 2D-Kamera- als auch 3D-Scandaten (Punktwolken) oder auch fusionierte Daten sein. Eine Vielzahl von Objektklassen (z.B. Gebäude, Baumstamm, Bordstein, Schiene) und Oberflächenklassen (z.B. Asphalt, Beton, Pflaster) können damit zuverlässig und in Echtzeit erkannt werden.
Je nach Datenbasis ist die Erstellung annotierter Trainingsdaten ein sehr aufwändiger, und überwiegend manueller Prozess. Um diesen Prozess effizienter zu gestalten, stehen verschiedene (selbst entwickelte) Tools und Strategien zur Verfügung.


